
LLM learning record about Tokenization and Embedding
Tokenization分词
Concept
- 分词的三种粒度:
- 词粒度:OOV问题,out of vocabulary,词表之外的词无能为力
- 字符粒度:词表小,例如26个英文字母、5000+中文常用字可以构成词表
- 子词粒度:介于char和word之间
Algorithm
Byte Pair Encoding (BPE)

https://arxiv.org/pdf/1508.07909
Key Point
- 从一个基础的小词表开始,不断通过合并最高频的连续token对产生新的token
- 缺点:
- 基于贪心的确定的符号替换策略,不能提供带概率的多个分词结果(相对ULM)
- 解码可能面临歧义
Code
import re, collections
text = "The aims for this subject is for students to develop an understanding of the main algorithms used in naturallanguage processing, for use in a diverse range of applications including text classification, machine translation, and question answering. Topics to be covered include part-of-speech tagging, n-gram language modelling, syntactic parsing and deep learning. The programming language used is Python, see for more information on its use in the workshops, assignments and installation at home."
# text = 'low '*5 +'lower '*2+'newest '*6 +'widest '*3
'''
先统计词频
'''
def get_vocab(text):
# 初始化为 0
vocab = collections.defaultdict(int)
# 去头去尾再根据空格split
for word in text.strip().split():
#note: we use the special token </w> (instead of underscore in the lecture) to denote the end of a word
# 给list中每个元素增加空格,并在最后增加结束符号,同时统计单词出现次数
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
print(get_vocab(text))
"""
这个函数遍历词汇表中的所有单词,并计算彼此相邻的一对标记。
EXAMPLE:
word = 'T h e <\w>'
这个单词可以两两组合成: [('T', 'h'), ('h', 'e'), ('e', '<\w>')]
输入:
vocab: Dict[str, int] # vocab统计了词语出现的词频
输出:
pairs: Dict[Tuple[str, str], int] # 字母对,pairs统计了单词对出现的频率
"""
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word,freq in vocab.items():
# 遍历每一个word里面的symbol,去凑所有的相邻两个内容
symbols = word.split()
for i in range(len(symbols)-1):
pairs[(symbols[i],symbols[i+1])] += freq
return pairs
"""
EXAMPLE:
word = 'T h e <\w>'
pair = ('e', '<\w>')
word_after_merge = 'T h e<\w>'
输入:
pair: Tuple[str, str] # 需要合并的字符对
v_in: Dict[str, int] # 合并前的vocab
输出:
v_out: Dict[str, int] # 合并后的vocab
注意:
当合并word 'Th e<\w>'中的字符对 ('h', 'e')时,'Th'和'e<\w>'字符对不能被合并。
"""
def merge_vocab(pair, v_in):
v_out = {}
# 把pair拆开,然后用空格合并起来,然后用\把空格转义
bigram = re.escape(' '.join(pair))
# 自定义一个正则规则, (?<!\S)h\ e(?!\S) 只有前面、后面不是非空白字符(\S)(意思前后得是没东西的),才匹配h\ e,这样就可以把Th\ e<\w>排除在外
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for v in v_in:
# 遍历当前的vocabulary,找到匹配正则的v时,才用合并的pair去替换变成新的pair new,如果没有匹配上,那就保持原来的。
# 比如pair当前是'h'和'e',然后遍历vocabulary,找到符合前后都没有东西只有'h\ e'的时候就把他们并在一起变成'he'
new = p.sub(''.join(pair),v)
# 然后新的合并的数量就是当前vocabulary里面pair对应的数量
v_out[new] = v_in[v]
return v_out
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokens
vocab = get_vocab(text)
print("Vocab =", vocab)
print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
#about 100 merges we start to see common words
num_merges = 100
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
# vocabulary里面pair出现次数最高的作为最先合并的pair
best = max(pairs, key=pairs.get)
# 先给他合并了再说,当然这里不操作也没什么,到merge_vocab里面都一样
new_token = ''.join(best)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
# add new token to the vocab
tokens[new_token] = pairs[best]
# deduct frequency for tokens have been merged
tokens[best[0]] -= pairs[best]
tokens[best[1]] -= pairs[best]
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
print('vocab, ', vocab)
def get_tokens_from_vocab(vocab):
tokens_frequencies = collections.defaultdict(int)
vocab_tokenization = {}
for word, freq in vocab.items():
# 看vocabulary里面的token频率,相当于上面的code中的tokens去除freq为0的
word_tokens = word.split()
for token in word_tokens:
tokens_frequencies[token] += freq
# vocab和其对应的tokens
vocab_tokenization[''.join(word_tokens)] = word_tokens
return tokens_frequencies, vocab_tokenization
def measure_token_length(token):
# 如果token最后四个元素是 < / w >
if token[-4:] == '</w>':
# 那就返回除了最后四个之外的长度再加上1(结尾)
return len(token[:-4]) + 1
else:
# 如果这个token里面没有结尾就直接返回当前长度
return len(token)
# 如果vocabulary里面找不到要拆分的词,就根据已经有的token现拆
def tokenize_word(string, sorted_tokens, unknown_token='</u>'):
# base case,没词进来了,那拆的结果就是空的
if string == '':
return []
# 已有的sorted tokens没有了,那就真的没这个词了
if sorted_tokens == []:
return [unknown_token] * len(string)
# 记录拆分结果
string_tokens = []
# iterate over all tokens to find match
for i in range(len(sorted_tokens)):
token = sorted_tokens[i]
# 自定义一个正则,然后要把token里面包含句号的变成[.]
token_reg = re.escape(token.replace('.', '[.]'))
# 在当前string里面遍历,找到每一个match token的开始和结束位置,比如string=good,然后token是o,输出[(2,2),(3,3)]?
matched_positions = [(m.start(0), m.end(0)) for m in re.finditer(token_reg, string)]
# if no match found in the string, go to next token
if len(matched_positions) == 0:
continue
# 因为要拆分这个词,匹配上的token把这个word拆开了,那就要拿到除了match部分之外的substring,所以这里要拿match的start
substring_end_positions = [matched_position[0] for matched_position in matched_positions]
substring_start_position = 0
# 如果有匹配成功的话,就会进入这个循环
for substring_end_position in substring_end_positions:
# slice for sub-word
substring = string[substring_start_position:substring_end_position]
# tokenize this sub-word with tokens remaining 接着用substring匹配剩余的sorted token,因为刚就匹配了一个
string_tokens += tokenize_word(string=substring, sorted_tokens=sorted_tokens[i+1:], unknown_token=unknown_token)
# 先把sorted token里面匹配上的记下来
string_tokens += [token]
substring_start_position = substring_end_position + len(token)
# tokenize the remaining string 去除前头的substring,去除已经匹配上的,后面还剩下substring_start_pos到结束的一段substring没看
remaining_substring = string[substring_start_position:]
# 接着匹配
string_tokens += tokenize_word(string=remaining_substring, sorted_tokens=sorted_tokens[i+1:], unknown_token=unknown_token)
break
else:
# return list of unknown token if no match is found for the string
string_tokens = [unknown_token] * len(string)
return string_tokens
"""
该函数生成一个所有token的列表,按其长度(第一键)和频率(第二键)排序。
EXAMPLE:
token frequency dictionary before sorting: {'natural': 3, 'language':2, 'processing': 4, 'lecture': 4}
sorted tokens: ['processing', 'language', 'lecture', 'natural']
INPUT:
token_frequencies: Dict[str, int] # Counter for token frequency
OUTPUT:
sorted_token: List[str] # Tokens sorted by length and frequency
"""
def sort_tokens(tokens_frequencies):
# 对 token_frequencies里面的东西,先进行长度排序,再进行频次,sorted是从低到高所以要reverse
sorted_tokens_tuple = sorted(tokens_frequencies.items(), key=lambda item:(measure_token_length(item[0]),item[1]), reverse=True)
# 然后只要tokens不要频次
sorted_tokens = [token for (token, freq) in sorted_tokens_tuple]
return sorted_tokens
#display the vocab
tokens_frequencies, vocab_tokenization = get_tokens_from_vocab(vocab)
#sort tokens by length and frequency
sorted_tokens = sort_tokens(tokens_frequencies)
print("Tokens =", sorted_tokens, "\n")
#print("vocab tokenization: ", vocab_tokenization)
sentence_1 = 'I like natural language processing!'
sentence_2 = 'I like natural languaaage processing!'
sentence_list = [sentence_1, sentence_2]
for sentence in sentence_list:
print('==========')
print("Sentence =", sentence)
for word in sentence.split():
word = word + "</w>"
print('Tokenizing word: {}...'.format(word))
if word in vocab_tokenization:
print(vocab_tokenization[word])
else:
print(tokenize_word(string=word, sorted_tokens=sorted_tokens, unknown_token='</u>'))
Byte-level BPE (BBPE)

https://arxiv.org/pdf/1909.03341
Key Point
- 将BPE算法从字符级别拓展到字节级别,即基础词表采用256的字节集,UTF-8编码
- 优点:
- 减少词表
- 多语言之间更好的共享
- 高效的文本压缩效果
- 可以适用不同类型的数据(图像、文本)
- 无损压缩、灵活、可解码性
- 缺点:
- 编码序列长度可能略微高于BPE
- byte解码可能有歧义,需要通过上下文信息和动态规划来decode
Code
https://gitee.com/wangyizhen/fairseq/blob/master/fairseq/data/encoders/byte_utils.py
https://gitee.com/wangyizhen/fairseq/blob/master/examples/byte_level_bpe/gru_transformer.py
import torch
import torch.nn as nn
import regex as re
import json
from collections import Counter
from concurrent.futures import ThreadPoolExecutor
def bytes_to_unicode():
"""
返回utf-8字节列表和到unicode字符串的映射。我们特别避免映射到bbpe代码所依赖的空白/控制字符。
可逆的bbpe代码在unicode字符串上工作。这意味着如果您想避免UNKs,您需要在您的词汇表中使用大量的unicode字符。
当你有一个10B的token数据集时,你最终需要大约5K才能获得良好的覆盖。这是你正常情况下的一个显著比例,
比如说,32K的词汇量。为了避免这种情况,我们希望查找表介于utf-8字节和unicode字符串之间。
"""
bs = (
list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(
range(ord("®"), ord("ÿ") + 1))
)
cs = bs[:]
n = 0
for b in range(2 ** 8):
if b not in bs:
bs.append(b)
cs.append(2 ** 8 + n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
class BBPETokenizer(nn.Module):
def __init__(self, vocab_path: str, merges_path: str):
super().__init__()
with open(vocab_path, "r", encoding="utf-8") as f: # 获得词表
vocab = json.load(f)
with open(merges_path, "r", encoding="utf-8") as f: # 获得合并token规则词表
merges = f.read()
# 将合并存储为元组列表,删除最后一个空白行
merges = [tuple(merge_str.split()) for merge_str in merges.split("\n")[:-1]]
# token到BBPE解码索引映射
self.encoder = vocab
self.decoder = {v: k for k, v in self.encoder.items()}
# 字节到unicode字符映射,256个字符
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
self.bbpe_ranks = dict(zip(merges, range(len(merges))))
self.cache = {}
# 预标记化拆分正则表达式模式
self.pat = re.compile(r"""
's|'t|'re|'ve|'m|'ll|'d| # 常见的收缩
\ ?\p{L}+|\ ?\p{N}+| # 可选空格,后跟1+ unicode字母或数字
\ ?[^\s\p{L}\p{N}]+| # 可选空格,后面跟着1+非空白/字母/数字
\s+(?!\S)| # 1+空白字符,后面没有非空白字符
\s+ # 1+空格字符
""", re.X)
def forward(self, text):
if isinstance(text, list):
# 批量编码
tokens = self.encode_batch(text)
tokens = [token for row in tokens for token in row]
else:
# 编码字符串
tokens = self.encode(text)
return torch.tensor(tokens)
def bbpe(self, token):
'''
对token应用合并规则
'''
if token in self.cache:
return self.cache[token]
chars = [i for i in token]
# 对于每个合并规则,尝试合并任何相邻的字符对
for pair in self.bbpe_ranks.keys():
i = 0
while i < len(chars) - 1:
if chars[i] == pair[0] and chars[i + 1] == pair[1]:
chars = chars[:i] + ["".join(pair)] + chars[i + 2:]
else:
i += 1
self.cache[token] = chars
return chars
def encode(self, text: str) -> list[int]:
'''
将字符串编码为BBPE token
'''
bbpe_tokens_id = []
# pattern使用要输入BBPE算法的正则表达式模式拆分文本
for token in re.findall(self.pat, text):
# 将token转换为其字节表示,将字节映射到其unicode表示
token = "".join(self.byte_encoder[b] for b in token.encode("utf-8"))
# 对token执行bbpe合并,然后根据编码器将结果映射到它们的bbpe索引
bbpe_tokens_id.extend(self.encoder[bpe_token] for bpe_token in self.bbpe(token))
return bbpe_tokens_id
def tokenize(self, text):
"""
获得编码后的字符
:param text: 文本
:return: 返回编码后的字符
"""
bbpe_tokens = []
# pattern使用要输入BBPE算法的正则表达式模式拆分文本
for token in re.findall(self.pat, text):
# 将token转换为其字节表示,将字节映射到其unicode表示
token = "".join(self.byte_encoder[b] for b in token.encode("utf-8"))
# 对token执行bbpe合并,然后根据编码器获得结果
bbpe_tokens.extend(bpe_token for bpe_token in self.bbpe(token))
return bbpe_tokens
def encode_batch(self, batch: list[str], num_threads=4):
'''
将字符串列表编码为BBPE token列表
'''
with ThreadPoolExecutor(max_workers=num_threads) as executor:
result = executor.map(self.encode, batch)
return list(result)
def decode(self, tokens) -> str:
if isinstance(tokens, torch.Tensor):
tokens = tokens.tolist()
text = "".join([self.decoder[token] for token in tokens])
text = bytearray([self.byte_decoder[c] for c in text]).decode("utf-8", errors="replace")
return text
@staticmethod
def train_tokenizer(data, vocab_size, vocab_outfile=None, merges_outfile=None):
"""
:param data: 训练文本
:param vocab_size: 保留词表的大小
:param vocab_outfile: 保存词表的文件名
:param merges_outfile: 保存合并字节的词表
"""
if vocab_size < 256:
raise ValueError("vocab_size must be greater than 256")
# 预标记数据
byte_encoder = bytes_to_unicode()
pat_str = r"'s|'t|'re|'ve|'m|'ll|'d| ?[\p{L}]+| ?[\p{N}]+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"
split_words = [
[byte_encoder[b] for b in token.encode("utf-8")] for token in re.findall(pat_str, data)
]
# 向词汇表中添加基本词汇
vocab = set(byte_encoder.values())
merges = []
# 构建词汇表,直到满足所需的词汇量
while len(vocab) < vocab_size:
print(len(vocab))
pair_freq = Counter()
# 找出最常见的一对
for split_word in split_words:
pair_freq.update(zip(split_word[:-1], split_word[1:]))
most_common_pair = pair_freq.most_common(1)[0][0]
# 更新词汇表和合并列表
new_token = most_common_pair[0] + most_common_pair[1]
vocab.add(new_token)
merges.append(most_common_pair)
# 对数据执行合并
new_split_words = []
for split_word in split_words:
i = 0
new_word = []
# 对于单词中的每个重字符,尝试合并
while i < len(split_word) - 1:
if (split_word[i], split_word[i + 1]) == most_common_pair:
new_word.append(new_token)
i += 2
else:
new_word.append(split_word[i])
i += 1
if i == len(split_word) - 1:
new_word.append(split_word[i])
new_split_words.append(new_word)
split_words = new_split_words
vocab = sorted(list(vocab))
# 保存文件
if merges_outfile != None:
with open(merges_outfile, "w", encoding="utf-8") as f:
for merge in merges:
f.write(merge[0] + " " + merge[1] + "\n")
if vocab_outfile != None:
with open(vocab_outfile, "w", encoding="utf-8") as f:
json.dump({v: i for i, v in enumerate(vocab)}, f, ensure_ascii=False)
WordPiece

https://arxiv.org/pdf/2012.15524
Key Point
- 类似BPE也是从一个小词表出发,但不根据频率来合并token对,而是定义一种“token间的互信息来进行合并”
- 合并两个相邻字词x和y,产生新的字词z,定义$$score=\frac{P(t_z)}{P(t_x)P(t_y)}$$
- 优点:
- 较好平衡词表大小和OOV问题
- 缺点:
- 对拼写错误非常敏感
- 对前缀支持不好(一种策略是将复合词拆开、前缀也拆开)
Code
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
from transformers import AutoTokenizer
#First, we need to pre-tokenize the corpus into words.
#Since we are replicating a WordPiece tokenizer (like BERT),
#we will use the bert-base-cased tokenizer for the pre-tokenization
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
print(word_freqs)
alphabet = []
for word in word_freqs.keys():
if word[0] not in alphabet:
alphabet.append(word[0])
for letter in word[1:]:
if f"##{letter}" not in alphabet:
alphabet.append(f"##{letter}")
alphabet.sort()
alphabet
print(alphabet)
# add special tokens
vocab = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"] + alphabet.copy()
splits = {
word: [c if i == 0 else f"##{c}" for i, c in enumerate(word)]
for word in word_freqs.keys()
}
def compute_pair_scores(splits):
letter_freqs = defaultdict(int)
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
letter_freqs[split[0]] += freq
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
letter_freqs[split[i]] += freq
pair_freqs[pair] += freq
letter_freqs[split[-1]] += freq
scores = {
pair: freq / (letter_freqs[pair[0]] * letter_freqs[pair[1]])
for pair, freq in pair_freqs.items()
}
return scores
pair_scores = compute_pair_scores(splits)
for i, key in enumerate(pair_scores.keys()):
print(f"{key}: {pair_scores[key]}")
if i >= 5:
break
best_pair = ""
max_score = None
for pair, score in pair_scores.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
print(best_pair, max_score)
def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
merge = a + b[2:] if b.startswith("##") else a + b
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
vocab_size = 70
while len(vocab) < vocab_size:
scores = compute_pair_scores(splits)
best_pair, max_score = "", None
for pair, score in scores.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
splits = merge_pair(*best_pair, splits)
new_token = (
best_pair[0] + best_pair[1][2:]
if best_pair[1].startswith("##")
else best_pair[0] + best_pair[1]
)
vocab.append(new_token)
print(vocab)
def encode_word(word):
tokens = []
while len(word) > 0:
i = len(word)
while i > 0 and word[:i] not in vocab:
i -= 1
if i == 0:
return ["[UNK]"]
tokens.append(word[:i])
word = word[i:]
if len(word) > 0:
word = f"##{word}"
return tokens
print(encode_word("Hugging"))
print(encode_word("HOgging"))
def tokenize(text):
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
encoded_words = [encode_word(word) for word in pre_tokenized_text]
return sum(encoded_words, [])
print(tokenize("This is the Hugging Face Course!"))
Unigram Language Model (ULM)
Key Point
- 初始化一个大词表,通过unigram语言模型计算删除不同subword造成的loss
- 保留loss较大,即重要性较高的subword
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
print(word_freqs)
char_freqs = defaultdict(int)
subwords_freqs = defaultdict(int)
for word, freq in word_freqs.items():
for i in range(len(word)):
char_freqs[word[i]] += freq
# Loop through the subwords of length at least 2
for j in range(i + 2, len(word) + 1):
subwords_freqs[word[i:j]] += freq
# Sort subwords by frequency
sorted_subwords = sorted(subwords_freqs.items(), key=lambda x: x[1], reverse=True)
print(sorted_subwords[:10])
token_freqs = list(char_freqs.items()) + sorted_subwords[: 300 - len(char_freqs)]
token_freqs = {token: freq for token, freq in token_freqs}
from math import log
total_sum = sum([freq for token, freq in token_freqs.items()])
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}
def encode_word(word, model):
best_segmentations = [{"start": 0, "score": 1}] + [
{"start": None, "score": None} for _ in range(len(word))
]
for start_idx in range(len(word)):
# This should be properly filled by the previous steps of the loop
best_score_at_start = best_segmentations[start_idx]["score"]
for end_idx in range(start_idx + 1, len(word) + 1):
token = word[start_idx:end_idx]
if token in model and best_score_at_start is not None:
score = model[token] + best_score_at_start
# If we have found a better segmentation ending at end_idx, we update
if (
best_segmentations[end_idx]["score"] is None
or best_segmentations[end_idx]["score"] > score
):
best_segmentations[end_idx] = {"start": start_idx, "score": score}
segmentation = best_segmentations[-1]
if segmentation["score"] is None:
# We did not find a tokenization of the word -> unknown
return ["<unk>"], None
score = segmentation["score"]
start = segmentation["start"]
end = len(word)
tokens = []
while start != 0:
tokens.insert(0, word[start:end])
next_start = best_segmentations[start]["start"]
end = start
start = next_start
tokens.insert(0, word[start:end])
return tokens, score
print(encode_word("Hopefully", model))
print(encode_word("This", model))
def compute_loss(model):
loss = 0
for word, freq in word_freqs.items():
_, word_loss = encode_word(word, model)
loss += freq * word_loss
return loss
print(compute_loss(model))
import copy
def compute_scores(model):
scores = {}
model_loss = compute_loss(model)
for token, score in model.items():
# We always keep tokens of length 1
if len(token) == 1:
continue
model_without_token = copy.deepcopy(model)
_ = model_without_token.pop(token)
scores[token] = compute_loss(model_without_token) - model_loss
return scores
scores = compute_scores(model)
print(scores["ll"])
print(scores["his"])
percent_to_remove = 0.1
while len(model) > 100:
scores = compute_scores(model)
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
# Remove percent_to_remove tokens with the lowest scores.
for i in range(int(len(model) * percent_to_remove)):
_ = token_freqs.pop(sorted_scores[i][0])
total_sum = sum([freq for token, freq in token_freqs.items()])
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}
def tokenize(text, model):
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in words_with_offsets]
encoded_words = [encode_word(word, model)[0] for word in pre_tokenized_text]
return sum(encoded_words, [])
print(tokenize("This is the Hugging Face course.", model))
常用的分词库
SentencePiece
Tokenizers
- normalization
清理、删除空格、删除变音符号、小写化、Unicode normalization
from tokenizers import normalizers
from tokenizers.normalizers import NFD, StripAccents, Lowercase
# 定义一个normalizer
normalizer = normalizers.Sequence([
NFD(), # Unicode正规化
StripAccents(), # 去除读音
Lowercase() # 转小写
])
# 使用normalizer处理字符串
normalized_text = normalizer.normalize_str("Hello how are ü?")
print(normalized_text) # Output: 'hello how are u?'
# 假设有一个tokenizer对象,可以将这个normalizer设置给它
# tokenizer.normalizer = normalizer # 更新到tokenizer里
- pre-tokenization
from tokenizers.pre_tokenizers import Whitespace, Digits
from tokenizers import pre_tokenizers
# 基础用法:仅使用空格分割
pre_tokenizer = Whitespace()
result = pre_tokenizer.pre_tokenize_str("Hello! How are you? I'm fine, thank you.")
print("仅使用Whitespace预分词器:")
print(result)
# 进阶用法:组合多个预分词器
pre_tokenizer = pre_tokenizers.Sequence([
Whitespace(), # 空格分割
Digits(individual_digits=True) # 数字分割(若individual_digits=False,"911"会保持为一个整体)
])
# 使用组合预分词器处理文本
result = pre_tokenizer.pre_tokenize_str("Call 911! How are you? I'm fine thank you")
print("\n使用组合预分词器(Whitespace + Digits):")
print(result)
# 假设有一个tokenizer对象,可以将这个pre_tokenizer设置给它
# tokenizer.pre_tokenizer = pre_tokenizer # 更新到tokenizer里
- model
设置具体的分词算法,例如tokenizer=Tokenizer(BPE(unk_token="[UNK]"))
- post-processing
后处理,实现比如加上special token([CLS]、[SEP])等
Total
- wordpiece和BPE的对比:
- 都是合并的思路,将语料拆分成最小单元(英文中26个字母加上各种符号,这些作为初始词表)然后进行合并,词表从小到大
- 核心区别就在于wordpiece是按token间的互信息来进行合并而BPE是按照token一同出现的频率来合并的
- wordpiece和ULM的对比:
- 都使用语言模型来挑选子词
- 区别在于前者词表由小到大,而后者词表由大到小,先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件
- ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个分词结果
Embedding 词嵌入
Concept
- Embedding的概念
nn.Embedding(vocab_size,embed_dim),vocab_size为词表大小、embed_dim为词向量的表征维度大小
Algorithm
Onehot
Key Point
- onehot为输入,稠密向量(即词向量)为输出
- 缺点:
- 词汇表过大,不能处理大规模文本数据
- 所有词向量之间彼此正交,无法体现词与词之间的相似关系
Word2Vec

https://arxiv.org/pdf/1301.3781
Key Point
- 通过训练,将原来onehot编码的每个词都映射到较短的词向量上,维度可以训练时自己指定
- 本质是只具有一个隐含层的神经元网络
- 两种任务类型:
- CBOW→根据上下文预测当前词
- Skip-gram→根据当前词预测上下文
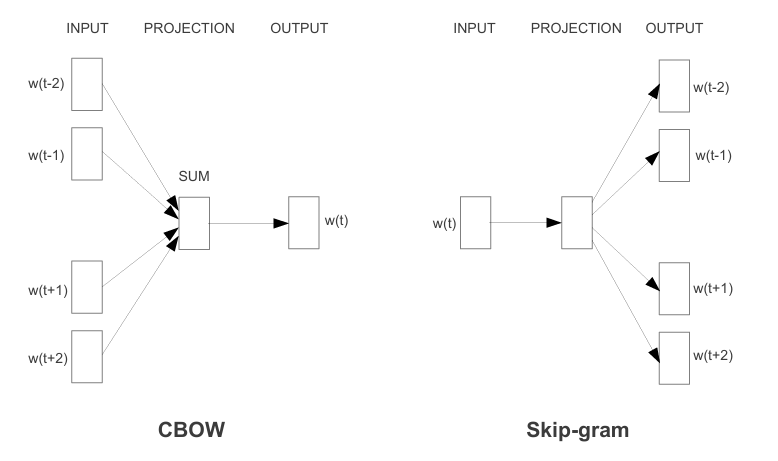
- 可以使用Hierarchical softmax和Negative Sample加速Word2Vec
FastText

https://arxiv.org/pdf/1607.01759
Key Point
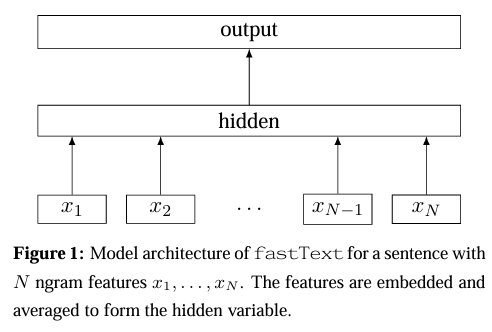
- 本质是一个快速文本分类算法,类似CBOW
- Loss function:交叉熵损失
- Hierarchical Softmax:根据文本类别的频率构造哈夫曼树代替标准的softmax,通过分层softmax将复杂度降低为对数级别