
LLM learning record about Transformer
从这部分开始逐渐了解Transformer模型
Attention 注意力

https://arxiv.org/pdf/1706.03762
https://blog.csdn.net/weixin_42426841/article/details/143472097
Concept
Query:寻找的信息Key:包含的信息Value:需要进行加权的信息- 序列当中某个位置的Query点积序列中其他所有位置的Keys,产生相应的权重,然后了解有关特定token的更多信息,而不是序列中任何其他token
Transformer中的Attention
Scaled Dot-Product
- $Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_k}})V$
- Scaled指的是对注意力权重进行缩放,具体是通过除以$\sqrt{d_k}$实现的
- 除以$\sqrt{d_k}$的原因:当Query和Key向量的维度$d_k$较大时,两个向量的长度比较长时,两个向量的相对差距变大,softmax之后值向两端(0和1)靠拢,类似onehot,计算梯度的时候比较小,容易跑不动
Self-Attention and Cross-Attention
- Encoder中的Self-Attention是当前位置token与序列全部token计算
- Decoder中的Self-Attention是当前位置的token只与在其之前的token计算(Mask Attention),避免解码过程中信息泄露
- 对decoder使用
kv cache,缓存之前序列token计算过的KV,避免重复计算
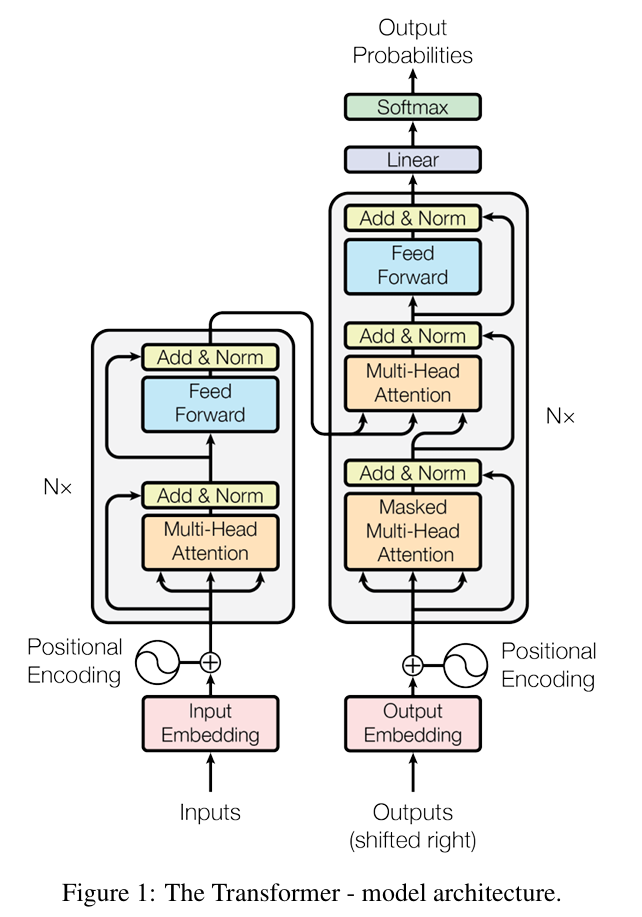
Multi-head Attention (MHA)
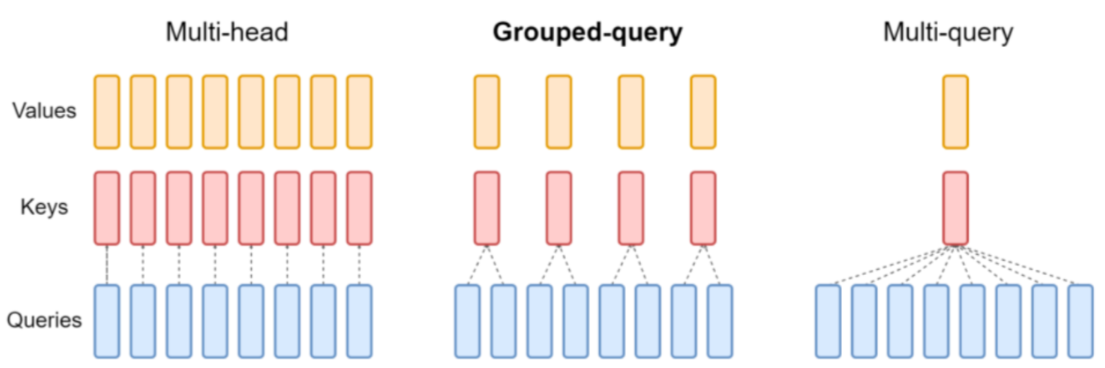
- DeepseekV2提出Multi-head Latent Attention优化MQA,解决了kv cache随着序列长度变长导致显存不足的问题

其他的Attention机制
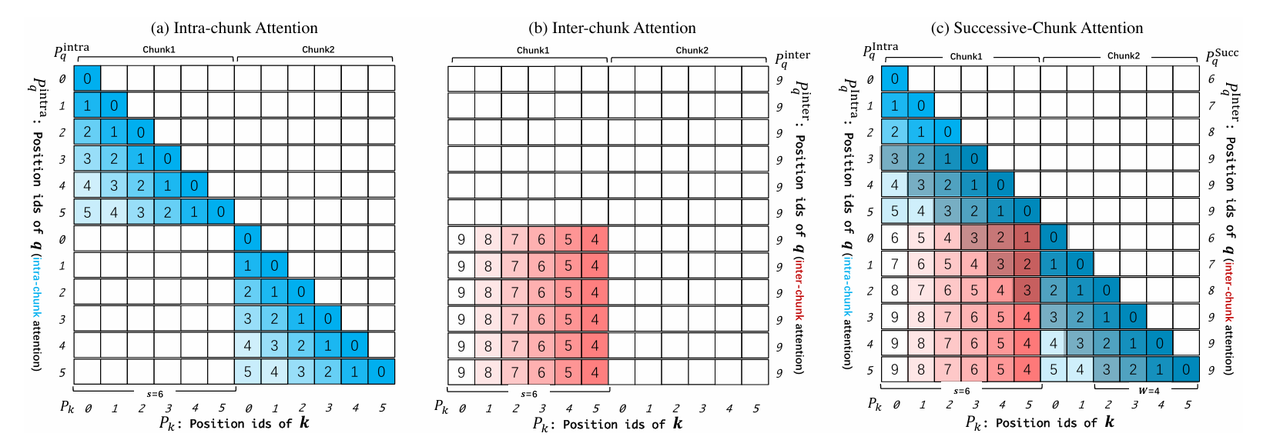
Dual Chunk Attention (DCA)

https://arxiv.org/pdf/2402.17463
- 将长文本分割成多个较小的“块”(chunks),然后在块内和块间分别应用注意力机制
import torch
import torch.nn as nn
class DualChunkAttention(nn.Module):
def __init__(self, embed_size, num_heads, chunk_size):
super(DualChunkAttention, self).__init__()
self.embed_size = embed_size
self.num_heads = num_heads
self.chunk_size = chunk_size
# 定义线性层
self.query = nn.Linear(embed_size, embed_size)
self.key = nn.Linear(embed_size, embed_size)
self.value = nn.Linear(embed_size, embed_size)
# 输出线性层
self.out = nn.Linear(embed_size, embed_size)
def split_into_chunks(self, x):
# 切分输入x为多个块(chunk),每个块大小为chunk_size
batch_size, seq_len, embed_size = x.shape
num_chunks = seq_len // self.chunk_size
chunks = x.view(batch_size, num_chunks, self.chunk_size, embed_size)
return chunks
def cross_block_attention(self, Q_chunks, K_chunks, V_chunks):
# 跨块注意力计算
batch_size, num_chunks, chunk_size, embed_size = Q_chunks.shape
cross_attn_out = []
# 计算每个块之间的注意力(查询块与所有键块)
for i in range(num_chunks):
# 取出查询块
q_chunk = Q_chunks[:, i, :, :] # (batch_size, chunk_size, embed_size)
# 计算该查询块与所有键块之间的注意力
attn_scores = torch.matmul(q_chunk, K_chunks.transpose(2, 3)) / (self.embed_size ** 0.5) # (batch_size, chunk_size, num_chunks, chunk_size)
attn_probs = torch.nn.functional.softmax(attn_scores, dim=-1) # (batch_size, chunk_size, num_chunks, chunk_size)
# 将注意力加权到值块上
cross_attn_out.append(torch.matmul(attn_probs, V_chunks[:, i, :, :])) # (batch_size, chunk_size, embed_size)
# 拼接所有块之间的跨块注意力输出
cross_attn_out = torch.cat(cross_attn_out, dim=1) # (batch_size, num_chunks * chunk_size, embed_size)
return cross_attn_out
def forward(self, x):
batch_size, seq_len, embed_size = x.shape
# 获取查询、键和值的表示
Q = self.query(x)
K = self.key(x)
V = self.value(x)
# 将Q, K, V分块
Q_chunks = self.split_into_chunks(Q)
K_chunks = self.split_into_chunks(K)
V_chunks = self.split_into_chunks(V)
# 计算每个块内的注意力(自注意力)
attn_out = []
for q_chunk, k_chunk, v_chunk in zip(Q_chunks, K_chunks, V_chunks):
# 计算每个块内的注意力
attn_scores = torch.matmul(q_chunk, k_chunk.transpose(-1, -2)) / (self.embed_size ** 0.5)
attn_probs = torch.nn.functional.softmax(attn_scores, dim=-1)
attn_out.append(torch.matmul(attn_probs, v_chunk))
# 拼接块内注意力结果
attn_out = torch.cat(attn_out, dim=2) # (batch_size, seq_len, embed_size)
# 计算跨块注意力
cross_attn_out = self.cross_block_attention(Q_chunks, K_chunks, V_chunks)
# 将跨块的注意力和块内的注意力融合
combined_out = attn_out + cross_attn_out # 可以进行加权求和或拼接
# 通过输出层
out = self.out(combined_out)
return out
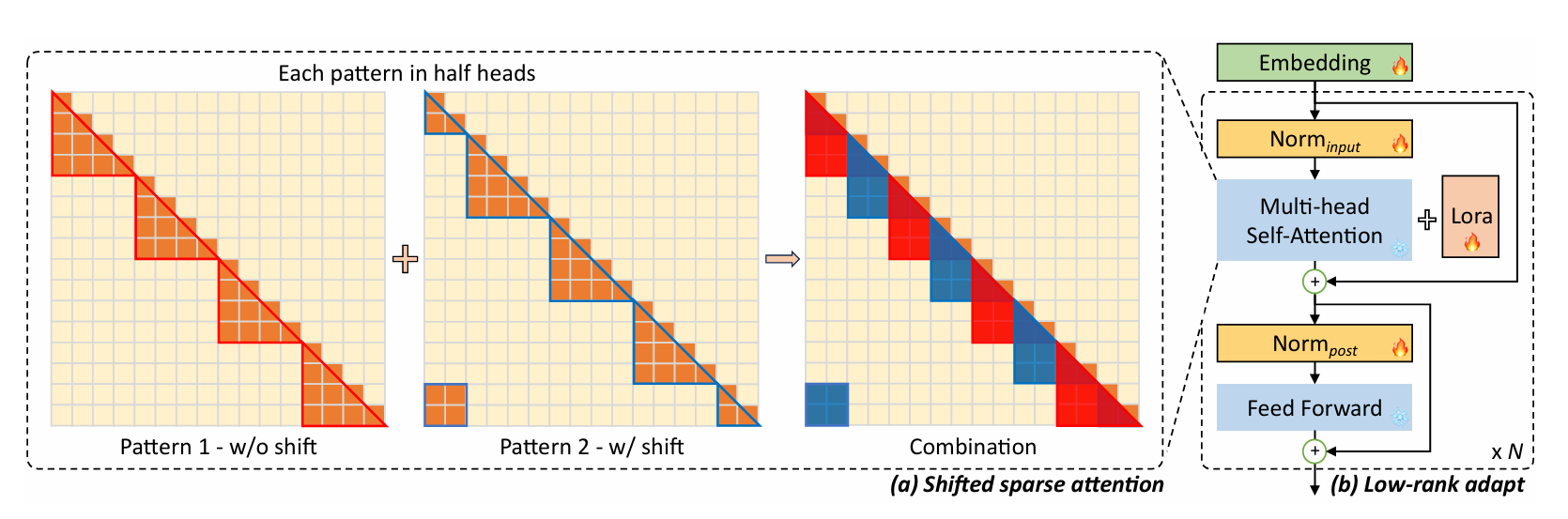
Shifted Soarse Attention (S2-Attention)

https://arxiv.org/pdf/2309.12307
- 将上下文分成几个组,每个组中单独计算注意力
- 在半注意力头中,将token按半组大小进行位移,保证相邻组之间的信息流动
- 虽然可能引入潜在的信息泄露,但可以通过对注意力掩码进行微调来避免
- https://github.com/dvlab-research/LongLoRA
FFN & Add & LN
这一部分我们讨论Transformer剩下几层的内容
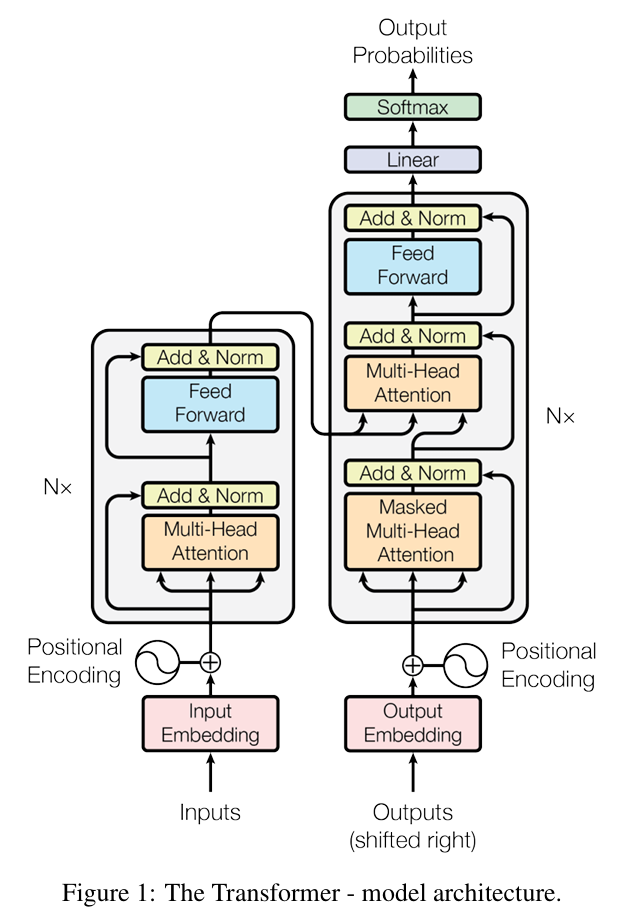
还是回到Transformer的这张结构图
Feed Forward Network
- Feed Forward Network:token通过MHA把信息聚合起来后,通过前馈网络思考学习这些信息(交流+计算)
- 一般激活函数的FFN计算公式:$$FFN(x)=ReLU(xW_1+b_1)W_2+b_2$$
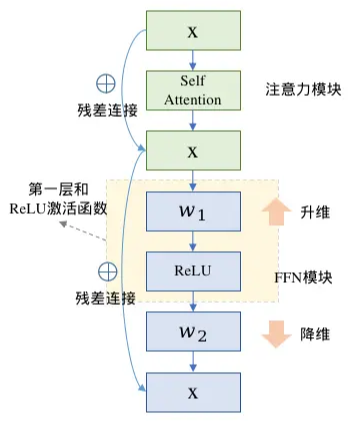
- GLU线性门控单元的FFN块计算公式:
- https://www.jianshu.com/p/2354873fe58a
- $GLU(x)=xV\cdot\sigma(xW+b)$
- $FFN_{GLU}=(xV\cdot\sigma(xW_1+b))W_2$
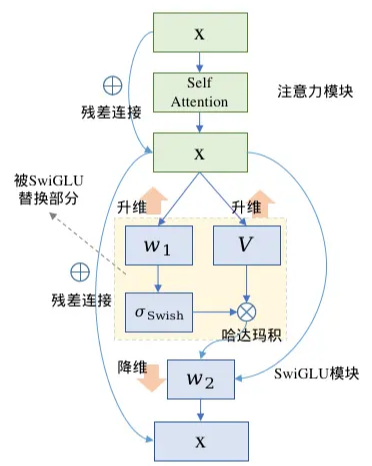
- SwiGLU、GeGLU指的是用Swish、GeLU激活函数替换GLU中的sigmoid激活函数,现在大模型通常使用SwiGLU替换传统的FFN结构
class LlamaMLP(nn.Module):
def __init__(
self,
hidden_size: int, # 4096
intermediate_size: int, # 11008
hidden_act: str, # silu
):
super().__init__()
self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)
self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
self.act_fn = ACT2FN[hidden_act]
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
常见的激活函数
- Sigmoid
- Tanh
- ReLU
- Leaky ReLU
- ELU
- Swish:$f(x)=x*sigmoid(x)$
- SwiGLU
- Softmax
Layer Norm
- Layer Norm层归一化:
- 加速模型收敛
- 缓解梯度消失和爆炸的问题
- Layer Norm一般用于NLP,Batch Norm一般用于CV,例如CV中Batch Norm是对一个图像的不同channel(例如RGB通道)各自归一化,这得益于CV任务本身不需要channel之间的信息交互https://blog.csdn.net/qq_36560894/article/details/115017087
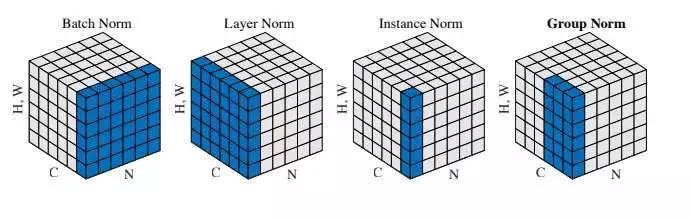
Layer Norm的位置
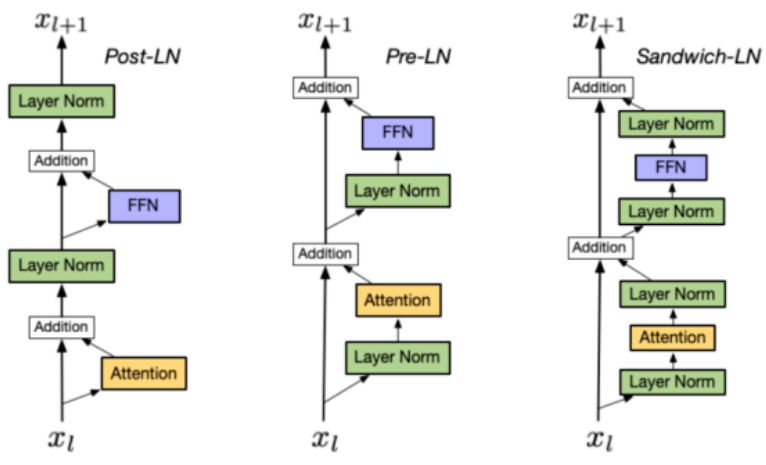
- Post Norm:
- 深层容易训练不稳定(梯度消失,初始化更新太大导致局部最优),深层的梯度范数逐渐增大
- 一般认为模型收敛性更好
- Pre Norm:
- 每层的梯度范数近似相等,训练稳定,但牺牲了深度
- 可以防止梯度爆炸或者梯度消失,大模型训练难度大,因此用Pre Norm较多
- Sandwich Norm:平衡,有效控制每一层的激活值,避免过大,能更好学习数据特征,但训练不稳定可能导致崩溃
- 相同设置下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm