
- Positional Encoding
- LLM Structure
- 解码采样策略
Positional Encoding
Transformer丢掉了时序信息,而一个句子中词与词之间的顺序不同会导致千差万别的语义,为了解决时序问题,Transformer的作者采用了Positional Encoding的办法,即位置编码
简单概括,Positional Encoding就是将位置信息嵌入到Embedding词向量中,让Transformer保留词向量的位置信息
进一步,我们期望得到一种位置表示方式,满足:
- 能用来表示一个token在序列中的绝对位置
- 在序列长度不同的情况下,不同序列中token的相对位置/距离也保持一致
- 可以用来表示模型在训练过程中从来没有看到过的句子长度,称为长度外推问题
绝对位置编码
Transformer的位置编码
- $PE_{t}=[sin(\omega_{0}t),cos(\omega_{0}t),sin(\omega_{1}t),cos(\omega_{1}t),\cdots,sin(\omega_{\frac{d_{model}}{2}-1}t),cos(\omega_{\frac{d_{model}}{2}-1}t)]$
- 采用正余弦函数交替进行位置编码
- 可以通过线性变换矩阵得到其他位置的表示,因为
$\begin{pmatrix}sin(t+\Delta t)\cr cos(t+\Delta t)\end{pmatrix}=\begin{pmatrix}cos\Delta t&sin\Delta t\cr -sin\Delta t&cos\Delta t\end{pmatrix}\begin{pmatrix}sint\cr cost\end{pmatrix}$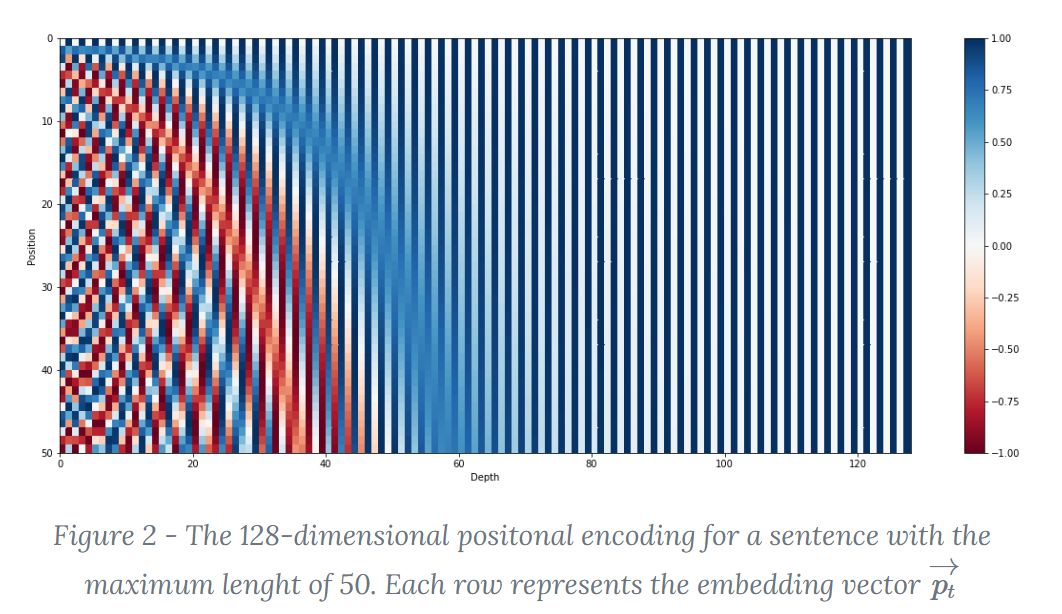
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
#pe.requires_grad = False
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
- Transformer位置编码的缺点:位置编码点积的无向性,$PE_{t}^{T}*PE_{t+\Delta t}=PE_{t}^{T}*PE_{t-\Delta t}$,即两个位置编码的乘积仅取决于$\Delta T$,不能用来表示位置的方向性
BERT的可学习位置编码
- 将位置编码当作可训练参数
- 缺点是没有长度外推性
Structure
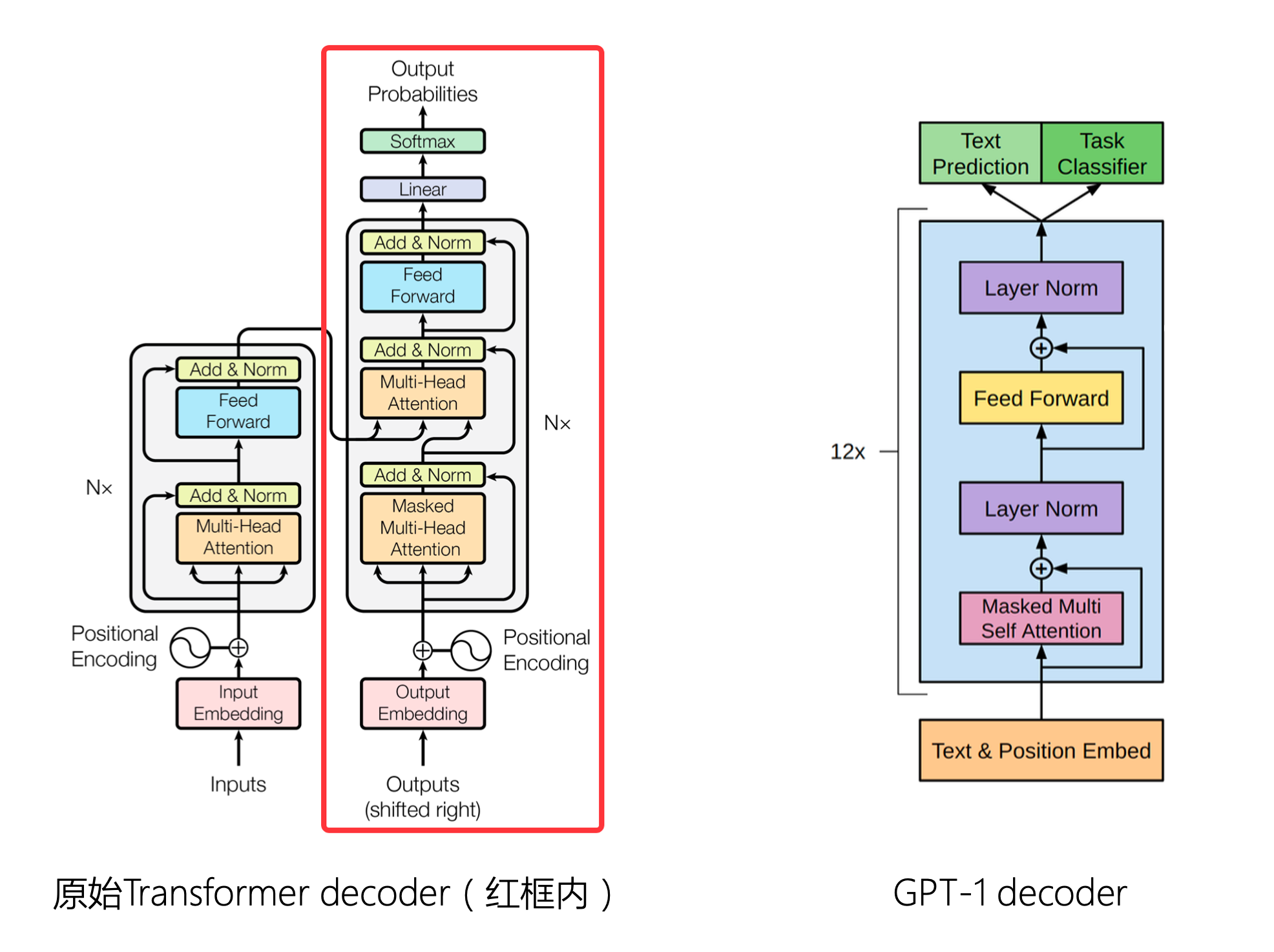
LLM的结构可以分为四类:
- Decoder-only
- 从左到右的单向注意力
- 自回归语言模型
- 文本生产效果好
- 训练效率高
- GPT、llama、BLOOM、OPT
- Encoder-only
- 经典模型BERT
- 目标是生成语言模型,预训练的语言模型
- Encoder-Decoder
- 输入双向注意力、输出单向注意力
- 对问题的编码理解更充分,在偏理解的任务上表现较好
- 训练效率低
- 文本生成任务表现差
- T5、Flan-T5、BART
- Prefix LM(特殊的Encoder-Decoder)
- GLM、U-PaLm
- MOE (Mixture of Experts)
- Deepseek V2/V3、Mistral
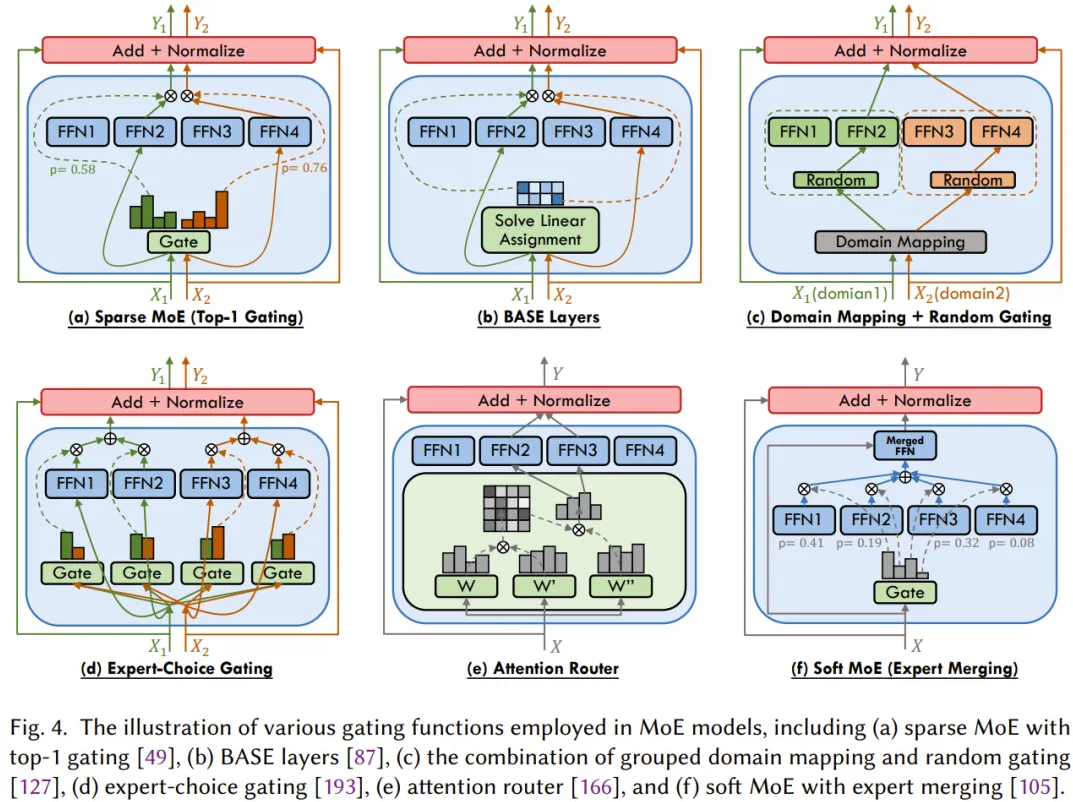
- Deepseek V2/V3、Mistral
解码采样策略
Greedy Search
- 每次选择概率最大的token解码
- 简单高效
- 导致生成的文本过于单调和重复
import torch
import torch.nn.functional as F
def greedy_search(logits, max_len=20, eos_token_id=2):
batch_size = logits.size(0)
seq_len = logits.size(1)
vocab_size = logits.size(2)
# 初始化生成的序列,存储每个时间步选择的词索引
generated_sequence = torch.zeros(batch_size, max_len, dtype=torch.long)
# 记录当前生成的序列,初始化为开始 token(一般为0或者某个特殊的起始符号)
current_input = torch.zeros(batch_size, dtype=torch.long) # 起始token id
for t in range(max_len):
# 获取当前步骤的 logits
current_logits = logits[:, t, :]
# 计算每个词的概率分布(通过softmax)
probs = F.softmax(current_logits, dim=-1)
# 选择概率最高的词索引(greedy)
next_token = torch.argmax(probs, dim=-1)
# 将选择的词加入到生成的序列中
generated_sequence[:, t] = next_token
# 检查是否遇到结束标记,若遇到则停止生成
if (next_token == eos_token_id).all():
break
# 更新当前输入(下一个时间步的输入)
current_input = next_token
return generated_sequence
Beam Search
- 维护一个大小为$k$的候选序列集合,每一步从每个候选序列的概率分布中选择概率最高的$k$个单词
- 保留总概率最高的$k$个候选序列
- 平衡生成的质量和多样性
- 可能导致生成的文本过于保守和不自然
def pred(input):
batch,seq_len=input.shape
generate=torch.randn(size=(batch,1,10))
return generate
def beam_search(input_ids,max_length,num_beams):
batch=input_ids.shape[0]
#输入扩展:效果是把input_ids复制成 batch_size * beam_size的个数
expand_size=num_beams
expanded_return_idx = (
torch.arange(input_ids.shape[0]).view(-1, 1).repeat(1, expand_size).view(-1).to(input_ids.device)
)
input_ids = input_ids.index_select(0, expanded_return_idx)
print(input_ids)
batch_beam_size,cur_len=input_ids.shape
beam_scores=torch.zeros(size=(batch,num_beams),dtype=torch.float,device=input_ids.device)
beam_scores[:,1:]=-1e9
beam_scores=beam_scores.view(size=(batch*num_beams,))
next_tokens=torch.zeros(size=(batch,num_beams),dtype=torch.long,device=input_ids.device)
next_indices=torch.zeros(size=(batch,num_beams),dtype=torch.long,device=input_ids.device)
while cur_len<max_length:
logits=pred(input_ids) #batch,seq_len,vocab
next_token_logits=logits[:,-1,:] #当前时刻的输出
#归一化
next_token_scores=F.log_softmax(next_token_logits,dim=-1) # (batch_size * num_beams, vocab_size)
#求概率
next_token_scores = next_token_scores + beam_scores[:, None].expand_as(next_token_scores) # 当前概率+先前概率
# reshape for beam search
vocab_size = next_token_scores.shape[-1]
next_token_scores = next_token_scores.view(batch, num_beams * vocab_size)
# 当前时刻的token 得分, token_id
next_token_scores, next_tokens = torch.topk(
next_token_scores, num_beams, dim=1, largest=True, sorted=True
)
next_indices = next_tokens // vocab_size #对应的beam_id
next_tokens = next_tokens % vocab_size #对应的indices
#集束搜索核心
def process(input_ids,next_scores,next_tokens,next_indices):
batch_size=3
group_size=3
next_beam_scores = torch.zeros((batch_size, num_beams), dtype=next_scores.dtype)
next_beam_tokens = torch.zeros((batch_size, num_beams), dtype=next_tokens.dtype)
next_beam_indices = torch.zeros((batch_size,num_beams), dtype=next_indices.dtype)
for batch_idx in range(batch_size):
beam_idx=0
for beam_token_rank, (next_token, next_score, next_index) in enumerate(
zip(next_tokens[batch_idx], next_scores[batch_idx], next_indices[batch_idx])
):
batch_beam_idx=batch_idx*num_beams+next_index
next_beam_scores[batch_idx, beam_idx] = next_score #当前路径得分
next_beam_tokens[batch_idx, beam_idx] = next_token #当前时刻的token
next_beam_indices[batch_idx, beam_idx] = batch_beam_idx #先前对应的id
beam_idx += 1
return next_beam_scores.view(-1), next_beam_tokens.view(-1), next_beam_indices.view(-1)
beam_scores, beam_next_tokens, beam_idx=process(input_ids,next_token_scores,next_tokens,next_indices)
# 更新输入, 找到对应的beam_idx, 选择的tokens, 拼接为新的输入 #(batch*beam,seq_len)
input_ids = torch.cat([input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
cur_len = cur_len + 1
#输出
return input_ids,beam_scores
if __name__ == '__main__':
input_ids=torch.randint(0,100,size=(3,1))
print(input_ids)
input_ids,beam_scores=beam_search(input_ids,max_length=10,num_beams=3)
print(input_ids)
Top-K Sampling
- 从排名前$k$的token中进行抽样,允许其他分数或概率较高的token被选中
- 将采样池限制为固定大小的k可能在分布比较尖锐的时候胡言乱语,另一方面在分布比较平坦的时候限制模型的创造力
#@torch.inference_mode()
@torch.no_grad()
def generate(self, idx,
eos, max_new_tokens, temperature=1.0, top_k=None):
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.params.max_seq_len else idx[:, -self.params.max_seq_len:]
# forward the model to get the logits for the index in the sequence
logits = self(idx_cond)##===================================
logits = logits[:, -1, :] # crop to just the final time step
if temperature == 0.0:
# "sample" the single most likely index
_, idx_next = torch.topk(logits, k=1, dim=-1)
else:
# pluck the logits at the final step and scale by desired temperature
logits = logits / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
if idx_next==eos:
break
return idx
Top-P Sampling
- 在累积概率超过设定值$P$的最小单词集中采样
import torch
import torch.nn.functional as F
def top_p_sampling(logits, p=0.9):
# 应用softmax得到概率分布
probs = F.softmax(logits, dim=-1)
# 对概率分布进行排序
sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)
# 计算累积概率
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
# 找到第一个使得累积概率大于p的位置
cutoff_idx = torch.sum(cumulative_probs <= p, dim=-1)
# 根据cutoff_idx截断概率分布
masked_probs = torch.gather(probs, dim=-1, index=sorted_indices[:, :cutoff_idx + 1])
# 重新归一化剩余概率
masked_probs = masked_probs / masked_probs.sum(dim=-1, keepdim=True)
# 从候选词中随机选择一个词
selected_idx = torch.multinomial(masked_probs, 1)
return sorted_indices.gather(-1, selected_idx)
Majority Vote
- 多数投票,输出多个回答,选择答案一致性最多的作为最终答案