
- 数据爬取
- 数据清洗
Pre Training Data
数据爬取
- 一些开源通用数据
| NAME | URL |
|---|---|
| Skywork/SkyPile-150B | https://huggingface.co/datasets/Skywork/SkyPile-150B |
| wikipedia-cn-20230720-filtered | https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered |
| C4 | https://github.com/allenai/allennlp/discussions/5056 |
| RedPajama | https://huggingface.co/datasets/togethercomputer/RedPajama-Data-V2 |
| WuDaoCorporaText | https://data.baai.ac.cn/details/WuDaoCorporaText |
| PRM800K | https://github.com/openai/prm800k?tab=readme-ov-file |
| YeungNLP/firefly-pretrain-dataset | https://huggingface.co/datasets/YeungNLP/firefly-pretrain-dataset |
- 定向网站爬虫demo
# -*- coding: utf-8 -*-
import io
import requests
from bs4 import BeautifulSoup
import urllib
import ssl
import pandas as pd
import tqdm
ssl._create_default_https_context = ssl._create_unverified_context
def download_pdf(save_path, pdf_name, pdf_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.146 Safari/537.36'
}
response = requests.get(pdf_url, headers=headers)
bytes_io = io.BytesIO(response.content)
with open("./事故报告_pdf/" + "%s.pdf" % pdf_name, mode='wb') as f:
f.write(bytes_io.getvalue())
print('%s.pdf,下载成功!' % (pdf_name))
def request_douban(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.146 Safari/537.36'
}
try:
response = requests.get(url=url, headers=headers, allow_redirects=False)
response.encoding = response.apparent_encoding
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
def askURL(url):
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36"}
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
if __name__ == '__main__':
save_path = './事故报告'
urls = []
for i in range(1, 117):
urls.append(f"https://openstd.samr.gov.cn/bzgk/gb/std_list_type?r=0.03316401348913578&page={i}&pageSize=10&p.p1=1&p.p6=13&p.p90=circulation_date&p.p91=desc")
names = []
nums = []
dodates = []
# q = tqdm(urls, desc='Processing')
for idx, url in enumerate(urls):
html = askURL(url)
bs = BeautifulSoup(html, 'html.parser')
contents = bs.find('table', class_='table result_list table-striped table-hover').find_all('tr')
for content in contents:
try:
th = content.find_all('td')
nums.append(th[1].text.strip())
names.append(th[3].text.strip())
dodates.append(th[6].text.strip()[:10])
except:
pass
print(f"完成第{idx}篇")
df = pd.DataFrame(columns=["编号","名称", "实施日期"])
for i in range(len(nums)):
df.loc[i] = [nums[i], names[i], dodates[i]]
df.to_csv('result.csv', index=False)
- 基于关键词爬取指定网站:https://github.com/NanmiCoder/MediaCrawler
数据清洗
- URL过滤(llama 3.1)
- 内容抽取:
- 得到过滤后的URL集合后,需要过滤、丢弃“目录”、“标题”、“广告”等无关内容
- 使用
trafilatura库进行内容抓取
from trafilatura import fetch_url,extract
url=""
downloaded=fetch_url(url)
result=extract(downloaded)
print(result)
- 语言识别:
使用
FastText训练一个语言识别模型,去掉语言阈值得分较低的文章使用
langid识别语言种类import landid text="abc" language=langid.classify(text)[0] print(language)使用
\data-juicer-main\data_juicer\ops\filter\language_id_score_filter.py进行识别from typing import List, Union from data_juicer.utils.constant import Fields, StatsKeys from data_juicer.utils.lazy_loader import LazyLoader from data_juicer.utils.model_utils import get_model, prepare_model from ..base_op import OPERATORS, Filter fasttext = LazyLoader('fasttext', 'fasttext') OP_NAME = 'language_id_score_filter' @OPERATORS.register_module(OP_NAME) class LanguageIDScoreFilter(Filter): """Filter to keep samples in a specific language with confidence score larger than a specific min value.""" def __init__(self, lang: Union[str, List[str]] = '', min_score: float = 0.8, *args, **kwargs): """ Initialization method. :param lang: Samples in which languages to keep. :param min_score: The min language identification confidence scores of samples to keep. :param args: extra args :param kwargs: extra args """ super().__init__(*args, **kwargs) if not lang: # lang is [], '' or None self.lang = None elif isinstance(lang, str): # lang is a single language string self.lang = [lang] else: # lang is a list of multiple languages self.lang = lang self.min_score = min_score self.model_key = prepare_model(model_type='fasttext') def compute_stats_single(self, sample): # check if it's computed already if StatsKeys.lang in sample[ Fields.stats] and StatsKeys.lang_score in sample[Fields.stats]: return sample text = sample[self.text_key].lower().replace('\n', ' ') ft_model = get_model(self.model_key) if ft_model is None: err_msg = 'Model not loaded. Please retry later.' raise ValueError(err_msg) pred = ft_model.predict(text) lang_id = pred[0][0].replace('__label__', '') lang_score = pred[1][0] sample[Fields.stats][StatsKeys.lang] = lang_id sample[Fields.stats][StatsKeys.lang_score] = lang_score return sample def process_single(self, sample): if self.lang: return sample[Fields.stats][StatsKeys.lang] in self.lang \ and sample[Fields.stats][StatsKeys.lang_score] >= \ self.min_score else: return sample[Fields.stats][StatsKeys.lang_score] >= self.min_score
- 低质过滤:
- 篇章级别过滤
- 句子级别过滤
- 模型打分:
- 利用模型对pretrain的数据指令进行打分(llama3、qwen2等)
- 相较于transformer-decoder,推荐使用BERT结构的模型,或者利用GPT4o等强闭源模型
- 给出DeepSeek-Math的流程作为参考
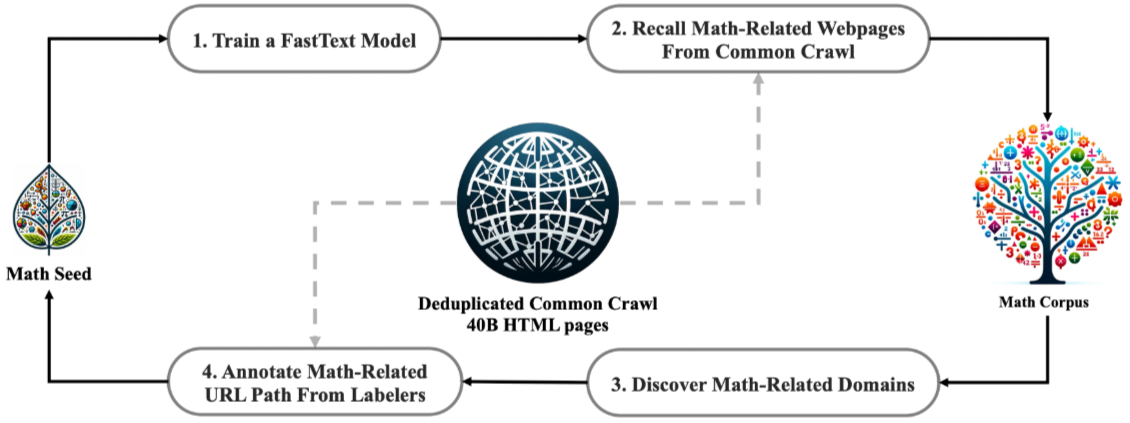
- 数据去重:
- 训练数据集中的重复
- 训练迭代设置的重复
- 训练与测试集的重复