- RAG概述
- RAG评估
- RAG优化策略:HyDE / Step Back Prompting / Multi Query Retrieval / Decomposition / CoVe / SAFE / DoLa
RAG概述
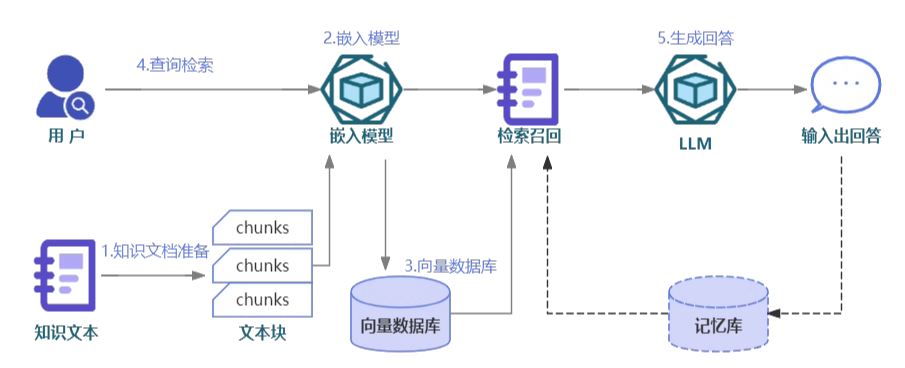
RAG流程
- 准备知识文档:
- 文档切片
- Embedding模型:
- 核心任务将文本转换为向量形式
- Word2Vec、BERT、GPT系列等
- 向量数据库
- 查询检索
- 生成回答
RAG分类
Retrieval-Augmented Generation for Large Language Models: A Survey

文中将RAG分为下文提及的三类
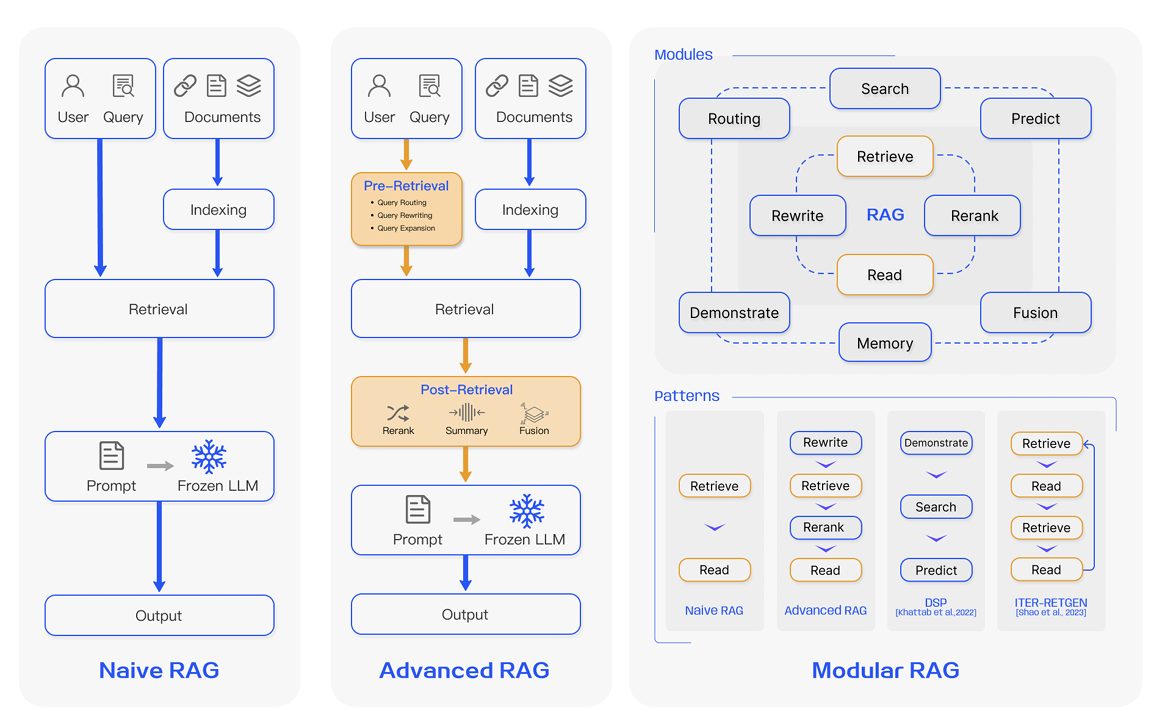
Naive RAG
- 经典的RAG,主要涉及“检索-阅读”过程
- 索引:将文档库分割为较短的chunk
- 检索:根据问题和chunk的相似度检索相关文档片段
- 生成:以检索到的上下文为条件,生成问题的回答
Advanced RAG
- 检索前:使用问题的重写、路由和扩充等方式对齐问题和文档块之间的语义差异
- 检索后:将检索得到的文档库进行重排序
Modular RAG
- 引入查询搜索引擎等更多功能模块
- 结合强化学习等技术
RAG评估
RAG难点问题
- 建立知识向量库:
- 如何切分不同类型的文件
- 如何设置chunk-size大小
- 选用何种向量化工具构建
- embedding模型是否需要微调
- …
- 检索优化:
- 如何应对模糊的、指向不明的问题
- 归纳总结:
- 内容全面性
- 生成内容格式
- 模型输出内容的可控性不够好
对检索环节的评估
MRR (Mean Reciprocal Rank)
- 用于评估根据查询返回的多个结果的相关性
- 定义结果列表中第$i$个结果匹配分数为$\frac{1}{i}$
def mean_reciprocal_rank(ranked_lists):
mrr = 0.0
for ranked_list in ranked_lists:
reciprocal_rank = 0
for rank, item in enumerate(ranked_list, start=1):
if item == 1: # Correct answer found
reciprocal_rank = 1 / rank
break
mrr += reciprocal_rank
return mrr / len(ranked_lists)
Hits Rate
- 前K项中包含正确信息的项的占比
- 可用于评估召回相关文档的比率
开源RAG评估框架
Ragas
Ragas主要评估忠实性、答案相关性、上下文相关性
https://blog.csdn.net/weixin_42608414/article/details/135355723
- 忠实性:答案应基于给定的上下文
- 答案相关性
- 上下文相关性:
- LLMs处理长篇上下文信息的成本高
- LLMs对于上下文段落中间提供的信息利用效率低
LangSmith
https://blog.csdn.net/fengshi_fengshi/article/details/144493414
可用来调试、测试、评估和监控基于任何LLM框架构建的chain和Agent
RAG优化
文档分块策略
RAG系统中,文档需要被分成多个文本块之后再进行向量嵌入
- 固定大小的分块
- 内容分块:
- 根据标点符号分块
- 使用NLTK、spaCy库的句子分割功能
- 递归分块:
- 通过重复运用分块规则递归地分解文本
- 例如:langchain先通过段落换行符
(\n\n)进行分割,进一步,对于大小超过阈值的块使用单换行符(\n)进行再次分割 - 如何制定合理的递归分块规则
- 特殊结构分块:
- 针对特定结构化内容的专门分块器
- langchain提供的特殊分块器:Markdown文件、LaTex文件、各种主流代码语言分块器
- 分块大小的选择:
- 不同的嵌入模型有不同的最佳输入大小,例如OpenAI的text-embedding-ada-002模型在256和512的分块上效果最佳
- 文档类型和用户查询长度以及复杂性也是决定分块大小的重要因素,例如长篇文章和书籍适合较大的分块,社交媒体帖子适合较小的分块
Embedding模型阶段
嵌入模型将文本转换成向量
可以参考Hugging Face给出的嵌入模型排行榜MTEB
https://huggingface.co/spaces/mteb/leaderboard
查询索引阶段(检索召回、重排)
用户的查询问题被转化为向量,检索过程中可能存在的问题:
- query和doc存在不对称问题
- query表达不清
- query过于具体,索引中不存在以回答该具体query为主要内容的doc
- query偏长尾、复杂,需要多步推理,索引中不存在能够直接提供答案的doc
基于上述存在的问题,我们可以从:
- Query Expansion
- StepBack
- Query Decomposation
- Multi Query Retrieval
等角度给出RAG优化策略
HyDE
假设文档嵌入

https://arxiv.org/pdf/2212.10496
- 接收到用户提问后,先让LLM在没有外部知识的情况下生成一个假设性回复
- 然后将这个假设性回复和原始查询一起用于向量检索
- 假设回复中虽然可能包含虚假信息,但蕴含着LLM认为相关的信息和文档模式,有助于在知识库中寻找类似的文档
- 生成伪文档
from langchain.prompts import ChatPromptTemplate
# HyDE document generation
template = """请撰写一段科学论文内容来回答以下问题。
Question: {question}
Passage:"""
prompt_hyde = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_docs_for_retrieval = (
prompt_hyde
| ChatOpenAI(temperature=0)
| StrOutputParser()
)
# Run
question = "LLM代理的任务分解是什么?"
generate_docs_for_retrieval.invoke({"question": question})
- 检索
# Retrieve
retrieval_chain = generate_docs_for_retrieval | retriever
retrieved_docs = retrieval_chain.invoke({"question": question})
retrieved_docs
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context": retrieved_docs, "question": question})
Step Back Prompting
退后提示

https://arxiv.org/pdf/2310.06117
- 原始查询太复杂、返回的信息太广泛,我们可以选择生成一个抽象层次更高的“退后问题”
- 将“退后问题”与原始问题一起用于检索,以增加返回结果的数量
- 例如“ABC在两年前就读于哪所学校”,可以给出退后问题:ABC的教育历史
- 构造few-shot
# Few Shot Examples
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
examples = [
{
"input": "Could the members of The Police perform lawful arrests",
"output": "what can the members of The Police do?",
},
{
"input": "Jan Sindel's was born in what country?",
"output": "what is Jan Sindel's personal history?",
},
]
# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
- 构造prompt
prompt = ChatPromptTemplate.from_messages(
[
("system", """你是一位世界知识领域的专家。你的任务是退一步,将问题改写为更通用的、便于回答的"退一步"问题。以下是一些示例:""",
),
# Few shot examples
few_shot_prompt,
# New question
("user", "{question}"),
]
)
generate_queries_step_back = prompt | ChatOpenAI(temperature=0) | StrOutputParser()
question = "LLM代理的任务分解是什么?"
generate_queries_step_back.invoke({"question": question})
# Response prompt
response_prompt_template = """你是一位世界知识领域的专家。我将向你提问一个问题。你的回答应当全面,并且在相关情况下不得与以下内容矛盾。如果这些内容与问题无关,则可以忽略它们。
# {normal_context}
# {step_back_context}
# Original Question: {question}
# Answer:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = (
{
# Retrieve context using the normal question
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,
# Retrieve context using the step-back question
"step_back_context": generate_queries_step_back | retriever,
# Pass on the question
"question": lambda x: x["question"],
}
| response_prompt
| ChatOpenAI(temperature=0)
| StrOutputParser()
)
chain.invoke({"question": question})
Multi Query Retrieval
多查询检索/多路召回
https://python.langchain.com/docs/how_to/MultiQueryRetriever/
- 使用LLM生成多个搜索查询
- 适用于一个问题需要依赖多个子问题
- Indexing
# Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
- Prompt构造
from langchain.prompts import ChatPromptTemplate
# Multi Query: Different Perspectives
template = """你是一款AI语言模型助手。你的任务是为用户提供的问题生成五个不同版本的改写,以便从向量数据库中检索相关文档。通过从多个较读改写用户问题,你的目标是帮助用户克服基于距离的相似性搜索的一些局限性。
请将这些改写问题用换行符分隔。原始问题:{question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_queries = (
prompt_perspectives
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
- 检索文档
from langchain.load import dumps, loads
def get_unique_union(documents: list[list]):
""" Unique union of retrieved docs """
# Flatten list of lists, and convert each Document to string
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# Get unique documents
unique_docs = list(set(flattened_docs))
# Return
return [loads(doc) for doc in unique_docs]
# Retrieve
question = "What is task decomposition for LLM agents?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
docs = retrieval_chain.invoke({"question": question})
len(docs)
- 内容生成
from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0)
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question": question})
Decomposition

https://arxiv.org/pdf/2305.14283
- 将一个复杂问题分解成多个子问题
- 可以按顺序串行解决(使用第一个问题的检索来回答第二个问题)
- 可以按并行解决(每个答案合并为最终答案),向下分解
- 构造答案迭代式回答的prompt
from langchain.prompts import ChatPromptTemplate
# Prompt
template = """Here is the question you need to answer:
\n --- \n {question} \n --- \n
Here is any available background question + answer pairs:
\n --- \n {q_a_pairs} \n --- \n
Here is additional context relevant to the question:
\n --- \n {context} \n --- \n
Use the above context and any background question + answer pairs to answer the question: """
decomposition_prompt = ChatPromptTemplate.from_template(template)
- 生成答案
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
def format_qa_pair(question, answer):
"""Format Q and A pair"""
formatted_string = ""
formatted_string += f"Question: {question}\nAnswer: {answer}\n\n"
return formatted_string.strip()
# llm
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
q_a_pairs = ""
for q in questions:
rag_chain = (
{"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
"q_a_pairs": itemgetter("q_a_pairs")}
| decomposition_prompt
| llm
| StrOutputParser()
)
answer = rag_chain.invoke({"question": q, "q_a_pairs": q_a_pairs})
q_a_pair = format_qa_pair(q, answer)
q_a_pairs = q_a_pairs + "\n--\n" + q_a_pair
生成回答阶段
- 减少模型产生主观回答和幻觉,RAG系统中的提示词应明确指出回答仅基于搜索结果,例如:“你是一名智能客服。你的目标是提供准确的信息,并尽可能帮助提问者解决问题。你应保持友善,但不要过于啰嗦。请根据提供的上下文信息,在不考虑已有知识的情况下,回答相关查询”
- 可以使用few-shot的方法,将想要的问答例子加入提示词中,从而指导LLM如何利用检索到的知识,提高模型在特定情境下的实用性
链式验证方法 (CoVe)
https://arxiv.org/pdf/2309.11495

https://zhuanlan.zhihu.com/p/675085581
- 模型首先生成基准回答(baseline answer)
- 生成验证问题来核实生成的结果
- 模型独立回答上述问题
- 最终生成验证后的回答

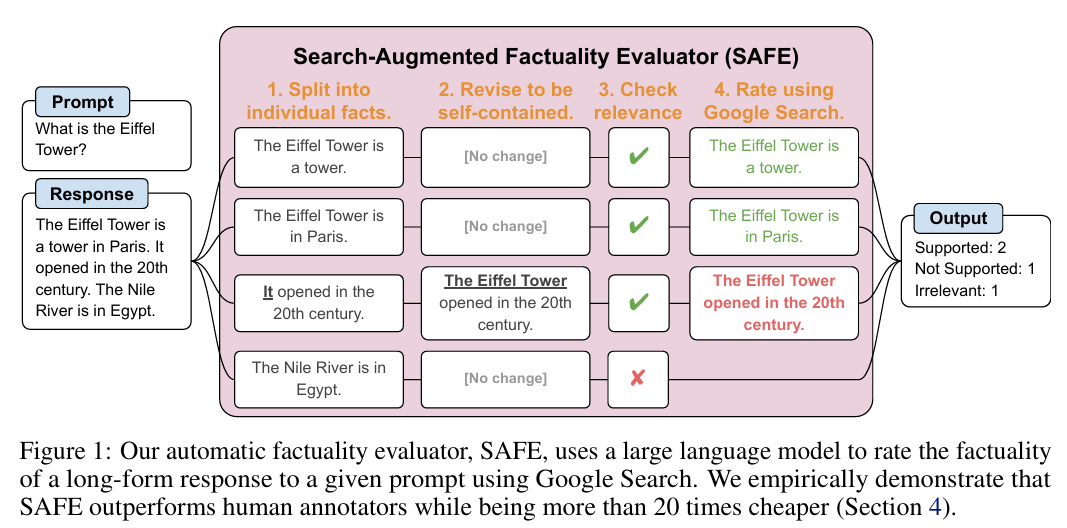
搜索增强事实 (SAFE)
https://arxiv.org/pdf/2403.18802
https://github.com/google-deepmind/long-form-factuality

- CoVe的升级方法,在链式验证中引入检索增强
- 通过将LLM生成的response拆分成多个事实,剔除与问题无关的事实内容
- 对每个相关事实进行检索增强,判断检索结果是否支持该事实
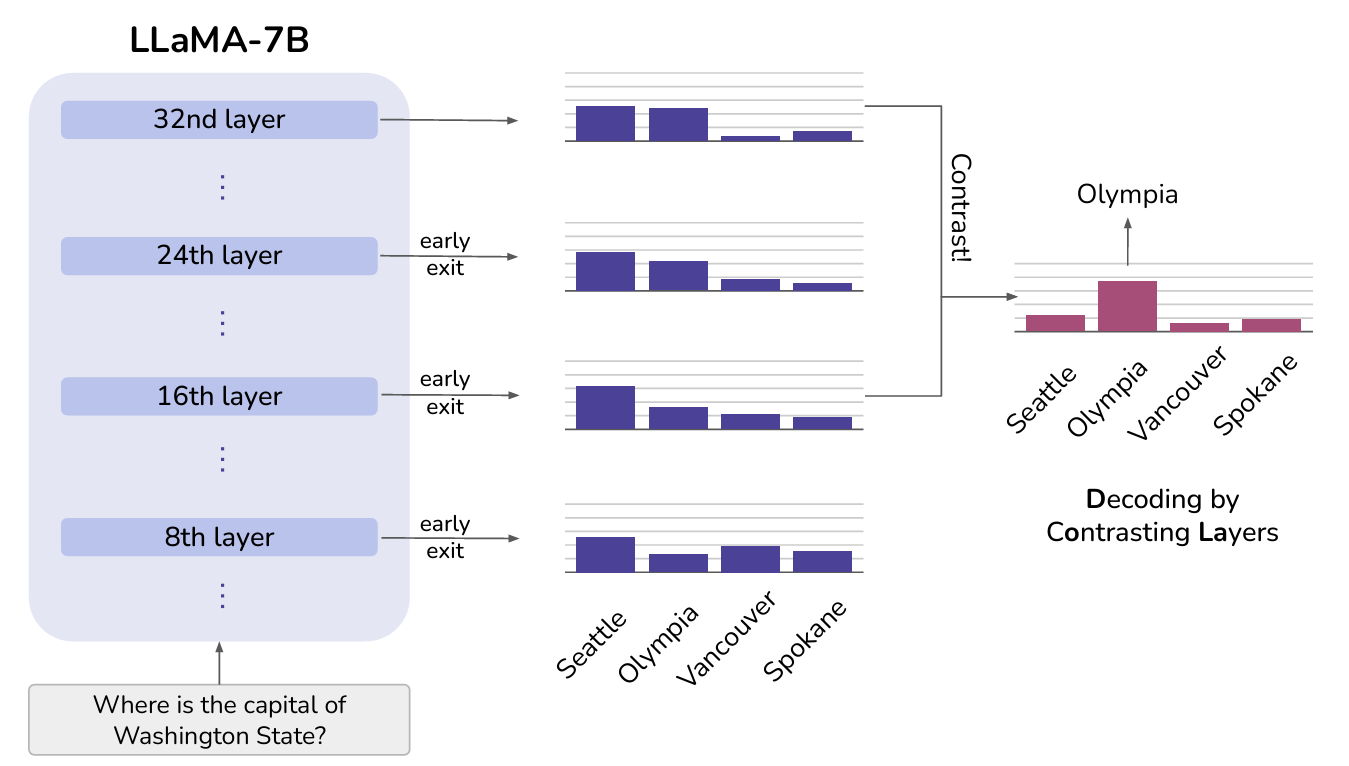
层对比解码 (Decoding by Contrasting Layers, DoLa)
https://arxiv.org/pdf/2309.03883
https://github.com/voidism/DoLa

- 在生成结果解码时同时关注Transformer高层与底层的知识
- 强调较高层中的知识并淡化低层中的知识
- 不检索外部知识或进行额外微调的情况下,有效减少语言模型的幻觉